1. 本記事の概要
AIエージェントは、近年のAI技術の発展により多くの分野で活用が進んでいます。本記事では、その基本構造や内部動作について、エンジニアやAIツール利用者向けに分かりやすく解説します。
本記事は概観を目的としています。AIエージェントから良い成果を得るには、良いコンテキストを与える必要があります。基本構造や内部動作に関する知識は、良いコンテキストを形成するのに役立ちます。
なお、本記事で扱うAIエージェントは、LLM(大規模言語モデル)を推論エンジンとし、ツール実行やコンテキスト管理を行う周辺システムと組み合わせて構成されたものを指します。
本記事では以下の流れで解説します。
- コンテキストがどのように構成されるか
- コンテキストの構成要素(システムプロンプト、エージェントプロンプト、ユーザープロンプト、参照情報)について
- すべての入力がベクトル表現に変換されること
- ベクトル表現は意味の情報しか持たないことによる課題
- コンテキストキャッシュの仕組み
- AIエージェントのファイル編集の仕組み
- 外部リンク(URL)の内容取得
注意: 分かりやすさと概観を重視しているため、不正確な簡略化を多分に含みます。正確な情報は各技術の公式ドキュメントを参照してください。
2. プロンプトの構成
全体図
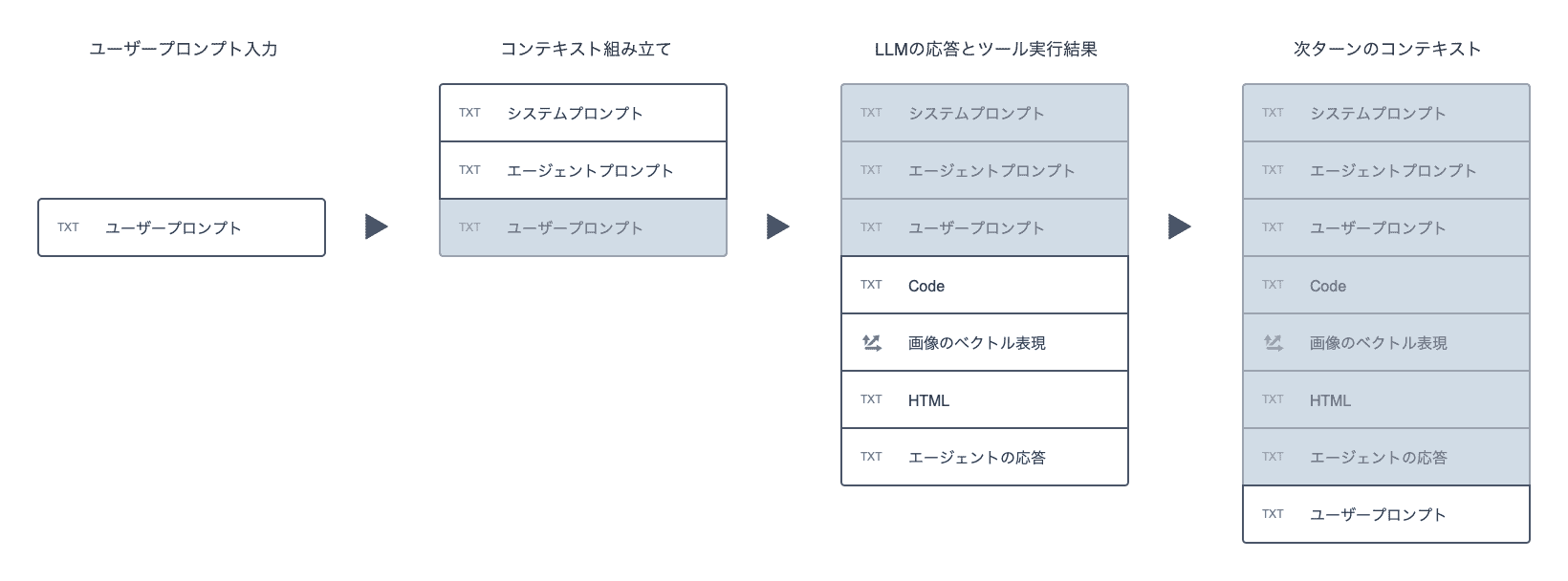
図のように、コンテキストは以下の流れで構成されます。
- ユーザーがプロンプトを入力する — ユーザーが質問や指示を入力します
- AIエージェントがシステムプロンプトとエージェントプロンプトを付加する — システムプロンプトや設定ファイルの内容が自動的にコンテキストへ付加されます
- LLMに入力される — 組み立てられたコンテキスト全体がLLMへの入力となります
- AIエージェントが必要な情報を追加する — AIエージェントが内部のLLMの判断に従ってファイルの読み取りや検索などのツールを実行し、その結果がコンテキストに追加されます
- LLMの出力が追加される — LLMの出力(回答やファイル編集の指示など)がコンテキストに追加されます
- ユーザーがプロンプトを追加する — ユーザーが次の指示や質問を入力します
- 3に戻る — システムプロンプトなどはコンテキスト先頭にあるものを使い回し、新しいやり取りが末尾に追加されていきます
システムプロンプト
システムプロンプトは、LLMの基本的な振る舞いを定義するプロンプトです。ツール提供者(OpenAI、Anthropicなど)が設定し、ユーザーからは通常見えません。
- エージェントの基本動作や役割を定義する(例:「あなたはソフトウェアエンジニアリングを支援するアシスタントです」)
- 使用可能なツールの一覧や使用権限、制約事項を設定する
- MCP(Model Context Protocol)サーバーの定義など、外部連携の設定を含む
エージェントプロンプト
エージェントプロンプトは、プロジェクト固有のルールや慣例をLLMに伝えるためのプロンプトです。以下のような設定ファイルに記述します。
AGENTS.md.github/copilot-instructions.md(GitHub Copilot)CLAUDE.md(Claude Code)
これらのファイルはセッション開始時に自動的にコンテキストに含まれます。プロジェクトのコーディング規約やディレクトリ構成のルールなどを記述しておくと、AIエージェントがそれに従って作業してくれます。
なお、エージェントプロンプトはセッション開始時にコンテキストに追加されるため、セッションの途中でファイルを変更しても反映されません。変更を反映するには新しいセッションを開始する必要があります。
ユーザープロンプト
ユーザープロンプトは、ユーザーが実際に入力するプロンプトです。質問、指示、コードの貼り付けなど、ユーザーがLLMに伝えたい内容そのものです。コンテキスト内ではシステムプロンプトやエージェントプロンプトの後に配置されます。
参照情報
参照情報は、AIエージェントがツールを利用してコンテキストに追加する情報です。AIエージェントが自律的に必要な情報を取得する仕組みをAgentic RAGと呼びます。
- コード: ファイルパス、参照行の情報、コードの内容などがテキストとして展開される
- 画像: 画像のベクトル表現が展開される
- HTML: LLMに解釈しやすいようにMarkdownなどに整形されテキストとして展開される
3. ベクトル表現
基本概要
LLMはすべての入力を数値ベクトル(数値の配列)に変換して処理します。この数値ベクトルは「Embedding vector(埋め込みベクトル)」とも呼ばれます。
- テキストはLLMによって直接ベクトル表現に変換されます
- 画像は専用のビジョンモデルによってベクトル表現に変換されます
ベクトル表現は対象の 「意味」 を数値で表現したものです。例えば、「犬」と「猫」のベクトルは「犬」と「自動車」のベクトルよりも近い位置に配置されます。LLMはこのベクトル表現をもとに推論を行います。
主な課題
ベクトル表現は「意味」を扱うため、正確な文字列マッチングとは異なる特性を持ちます。これにより、以下の2つの課題が生じます。
コードベース検索の精度
GitHub CopilotのWorkspace Indexでは、コードベース全体をベクトルデータベースに変換し、RAG(Retrieval-Augmented Generation)による検索に利用しています。
RAGを利用した検索はテキストそのものではなく「意味」を検索します。このため、存在しない関数名で検索をかけると、意味的に類似した別の関数を見つけてくることがあるそうです。これはハルシネーション(幻覚)のように見える現象です。ただし、筆者の検証では再現できなかったため、現在の精度では実用上問題にならない可能性があります。
Claude CodeやGitHub Copilot Agent Modeでは、ベクトル検索に頼らずgrep等のテキスト検索ツールを活用することで、このような問題を回避しているようです。
画像認識(Vision)の精度
LLMが画像を処理する際、専用のビジョンモデルによって画像の 「意味」 がベクトル化されます。このベクトル表現には、微妙な配置の違いやレイアウトの崩れが認識されにくいという特性があるようです。たとえば、1行だけテキストが右にずれたHTMLテーブルのスクリーンショットをLLMに提示しても、ずれを指摘しないことがあります。ただし、明示的に指示すれば認識できるようなので、全体像がぼんやり見えていて、指示があれば細部も確認できる状態なのではないかと考えています。
こうした認識のされ方は、コードベース検索と同様に「意味」を扱うベクトル表現に起因すると考えられます。実用面では、画像でしか伝えられない情報(全体のデザインや図の構造など)を除き、可能な範囲でテキストやHTMLとして情報を渡すと精度を確保しやすくなります。
4. AIエージェントの内部動作
コンテキストキャッシュ
コンテキストキャッシュは「KVキャッシュ(Key-Valueキャッシュ)」とも呼ばれ、LLMの推論を効率化する仕組みです。
コンテキストの先頭から指定した位置までの内容をキャッシュできます。これにより、同じコンテキストの先頭部分を共有するリクエストでは、キャッシュされた部分の再計算が不要になります。
この仕組みから、以下の特性があります。
- コンテキスト末尾への追記(会話の継続)はキャッシュを活用できるため効率的
- コンテキスト先頭付近の変更(システムプロンプトの変更など)はキャッシュがほぼ無効化されるため非効率
システムプロンプトやエージェントプロンプトがコンテキストの先頭に配置されるのは、キャッシュの恩恵を最大化するためでもあると思います。
ファイル編集の仕組み
AIエージェントはファイルを直接編集するのではなく、ファイル編集ツールの呼び出しという形式でファイル編集を行います。
具体的には、LLMがパッチファイルのような編集指示を出力し、編集ツールがその指示に従ってファイルを編集します。LLMは行番号やインデントなどを正確に扱うのが苦手なため、多くの編集ツールでは検索と置換を中心とした形式が採用されています。
問題なく編集を完了させるには意外とハードルがあります。例えば、整合性を保つために、AIエージェントがファイルを読み込んだ後に別のプロセスが同じファイルを変更していた場合、編集を失敗させて再読み込みを促す仕組みが導入されています。
実践的なヒント
大量のファイルに対して一様で確実な編集が必要な場合は、AIエージェントに直接編集させるよりもコマンドやスクリプトを生成させる方が効率的です。
- AIエージェントによるファイル編集は1ファイルずつ処理されるため、大量編集では高コストになる
sedやPythonスクリプトなどを生成させれば、一貫性のある編集を高速に実行できる
外部リンク(URL)の内容取得
AIエージェントはURLが与えられると、Webページの内容を自動的に取得して解析できます。
取得したHTMLはLLMが解釈しやすいようにMarkdown形式などに変換され、テキストとしてコンテキストに追加されます。これにより、ドキュメントページやAPIリファレンスなどの外部情報を参照しながら作業を進めることができます。
まとめ
AIエージェントから良い成果を得るには良いコンテキストを与えることが重要です。本記事で触れたコンテキストの構成要素、ベクトル表現の特性、内部動作の仕組みは、適切なコンテキストを形成するための土台となります。
本記事がお役に立てば幸いです。